728x90
반응형
데이터 분석을할때,
이미 준비된 데이터를 가져다 쓸수도있고 (공공데이터 캐글 등)
필요하다면 특정 페이지를 긁어오는 작업이 필요했는데.
이게 페이지마다 코드가 유동적으로 바뀌니..
재활용성은 떨어지더라두 분명이 스크래핑이 필요한 순간이 있다.
천천히 연습해보겠다.
꽤 다양한 방법으로 긁어오더라.
** 웹 문서 전체를 가지고와서 css selecter를 이용하기 **
1. BeautifulSoup객체를 이용해서 웹문서를 파싱한다.
2. 웹 문서가 태그 별로 분해되어 태그로 구성된 트리가 생기는데. 거기서 원하는 태그를 가져다 쓰면된다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.naver.com")
bsObject = BeautifulSoup(html, "html.parser")
print(bsObject)
3. 여기서 원하는 태그만 불러올수도 있다. 타이틀만 추출하고싶다면
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.naver.com")
bsObject = BeautifulSoup(html, "html.parser")
print(bsObject.head.title)
4. meta에 해당하는 값만 가져오고싶다면
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.naver.com")
bsObject = BeautifulSoup(html, "html.parser")
for meta in bsObject.head.find_all('meta'):
print(meta.get('content'))
5. 원하는 태그의 내용을 가져오기
** find를 사용한다.
meta태그 중 가져올 태그를 name속성 값이 description인 것으로 한정합니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.naver.com")
bsObject = BeautifulSoup(html, "html.parser")
print (bsObject.head.find("meta", {"name":"description"}).get('content'))
6. 모든 링크의 텍스트와 주소 가져오기
a 태그로 둘러쌓인 텍스트와 a태그의 href 속성을 출력한다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.naver.com")
bsObject = BeautifulSoup(html, "html.parser")
for link in bsObject.find_all('a'):
print(link.text.strip(), link.get('href'))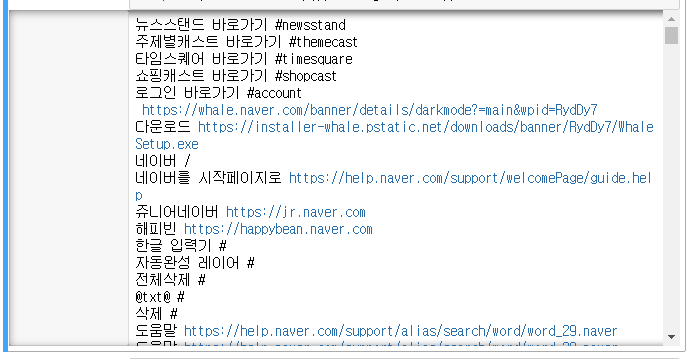
참고한 블로그
728x90
반응형
'활동 > 개인 프로젝트' 카테고리의 다른 글
| [scrapping] 페이지를 긁어보자. (2)_무신사추천상품 (0) | 2021.07.28 |
|---|

댓글